Rants of a Snake Charmer - III
XmlParser
This is a minimal XML parser that does what it is supposed to. The implementation is based on regular expressions. It is adapted from REX by Robert D. Camron.
Background
When Google Maps used to send the data objects needed by their AJAX framework in plain XML, I needed an XML parser to get location/directions data from the Google Maps server. In my earlier blog, I mentioned that PyS60 can seamlessly take modules from the desktop Python. But there are certain exceptions to that and the XML framework in Python happens to be one of them. I tried improting Python XML framework to PyS60 without any success and hence needed to find my own solution. As mentioned earlier, this XML Parser implementation is based on REX. I found REX when I was searching for the best approach to my solution. Robert Cameron has a set of regular expressions that can be used - very easily and effectively - to parse XML content. The following copyright notice and the license appear in the code.
# Robert D. Cameron "REX: XML Shallow Parsing with Regular Expressions",
# Technical Report TR 1998-17, School of Computing Science, Simon Fraser
# University, November, 1998.
# Copyright (c) 1998, Robert D. Cameron.
# The following code may be freely used and distributed provided that
# this copyright and citation notice remains intact and that modifications
# or additions are clearly identified.
The regular expressions for parsing the XML file are not modified in any way. Only the language in which the RE are implemented is changed to Python. The RE support is included in the PyS60 package.
The technical report can be found here.
Usage
XmlParser.py: This module can be used to
- Parse an XML file
- Parse an XML string
XMLNode Class
addProperty(property, value)
Adds a property and its value to the node. The property is added as an entry to the "properties" dictionary
addChild(tag, node)
Adds a child to the current node that can be accessed by the "tag". If there is more than one child to the current node by the same "tag", the children are added as an array in the order each child is encountered
setContent
Sets content of the current node. If the current node already contains content, then this content is appended to it
properties
A dictionary containing properties and their values of the current node
childnodes
A dictionary containing arrays containing children indexed by their tags
content
The actual content inside the tags
XMLParser Class
parseXMLFile(file)
Parses an XML file
parseXML(xmlBuffer)
Parses XML buffer passed as a string
getElementsByTagName(tag)
Traverses the minimal DOM tree PREorder and returns the array containing node(s) having "tag" name
root
Holds the root of the DOM tree
The user can decide to disregard some tags (not include them in the DOM tree) by adding them to the following array:
# Unsupported tags (HTML formatting tags for displaying info)
unSupportedTags = ['b', 'i', 'u']
Example Usage
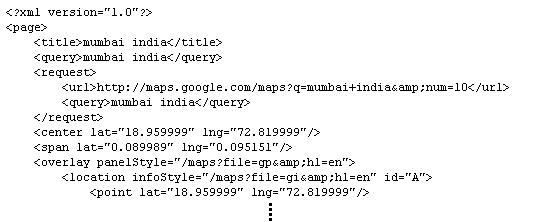
Example XML file:
<?xml version="1.0"?>
<page>
<title>mumbai india</title>
<query>mumbai india</query>
<request>
<url>http://maps.google.com/maps?q=mumbai+india&num=10</url>
<query>mumbai india</query>
</request>
<center lat="18.959999" lng="72.819999"/>
<span lat="0.089989" lng="0.095151"/>
<overlay panelStyle="/maps?file=gp&hl=en">
<location infoStyle="/maps?file=gi&hl=en" id="A">
<point lat="18.959999" lng="72.819999"/>
<icon class="noicon"/>
<info>
<address>
<line>Bombay</line>
<line>India</line>
</address>
</info>
</location>
</overlay>
</page>
To find out the "lat" and "lng" properties of "point" element:
...
locxml = ... Above XML ...
parser = XMLParser()
parser.parseXML(locxml)
pointNode = parser.getElementsByTagName('point')
if pointNode is None:
appuifw.note(u'Address not found', 'error')
else:
addressNode = parser.getElementsByTagName('address')
lines = []
if addressNode is not None:
lineNodes = addressNode.childnodes['line']
for node in lineNodes:
lines.append(node.content)
lat = float(pointNode.properties['lat'])
lng = float(pointNode.properties['lng'])
...
Summary
This little module is an evidence that with minimal effort, complex things can be done with the help of PyS60 on your handset.
posted by Nikhil Vajramushti at 8:38 PM
5 comments
![]()



